Salman Sayeed
Incoming CS PhD @ UofT
A dedicated NLP-HCI researcher focused on social AI, human-centered computing, and responsible AI, with a strong commitment to developing technologies that are ethical, inclusive, and impactful. Alongside my academic research, I bring extensive industry leadership experience, currently serving as an AI Engineering Manager at one of Bangladesh’s leading telecom operators (Banglalink), where I lead the design and deployment of large-scale AI solutions in real-world environments. Beginning in Fall 2026, I will be joining Dr. Ishtiaque Ahmed’s Lab at the University of Toronto as a PhD student, where I aim to advance research at the intersection of AI, society, and human experience.

"This photo was taken at Tour Eiffel after my particiaption at CHItaly 2025"
My Research & Publications
I started my research journey just before my graduation and following is a small list of the works that I have done till date. Feel free to reach out if you're interested for collaboration :D
Conference Publications
01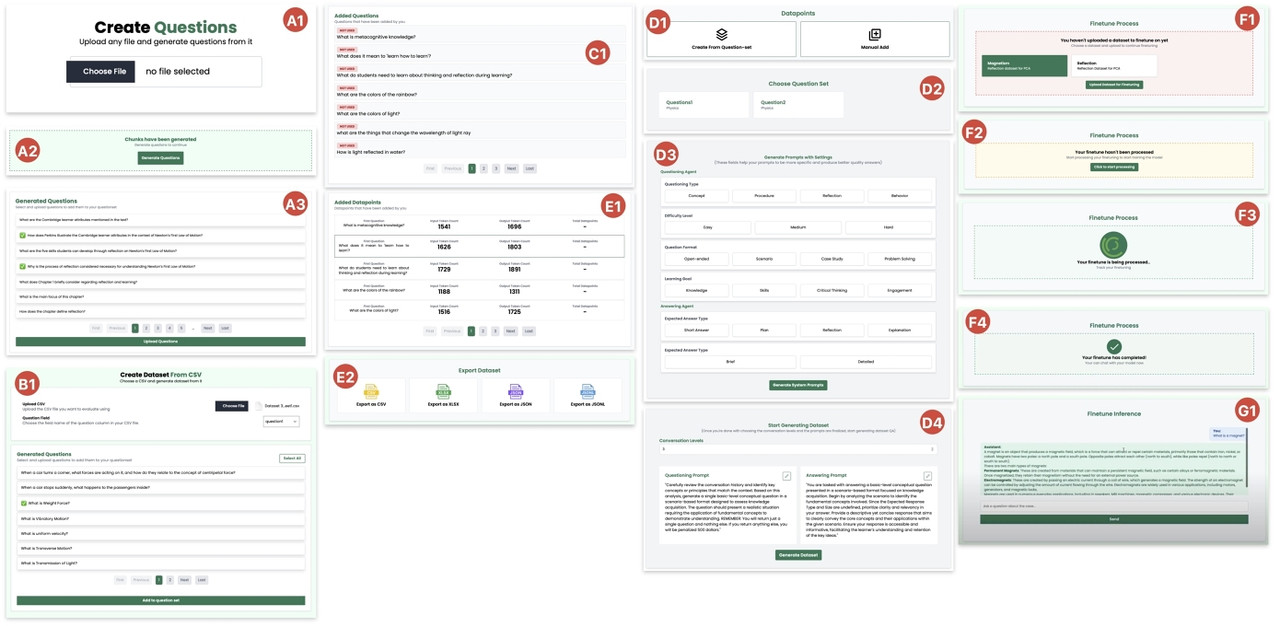
NuevAI: Streamlined Dataset Generator and Human Evaluator System for Development of Pedagogical Conversational Agents
The development of Pedagogical Conversational Agents (PCAs) made significant progress due to the rise of Large Language Models (LLMs). Yet, creating and evaluating PCAs remains a technically challenging task for educators. Our work presents a semi-autonomous system, NuevAI; designed to democratize the access to AI-enhanced educational tools by simplifying the development of PCAs. NuevAI consists of two complementary platforms that help educators create structured, multi-turn conversational datasets from various data sources for fine-tuning LLMs and also facilitates systematic assessment of PCA conversations by learners. From the evaluation of 16 educators from STEM subjects, our system shows notable improvements compared to traditional methods: 74.5% usability score (vs. 50.9% baseline), 81.2% task efficiency (vs. 49.1%), and 80.8% time efficiency (vs. 32.5% baseline). The system achieved a Net Promoter Score of 68.8% (vs. -62.5% baseline) and reduced cognitive workload by 40% as measured by NASA-TLX assessment. By providing user-friendly and intuitive interfaces and automated workflows, NuevAI empowers educators to create adaptive learning tools through PCAs, aligned with specific pedagogical objectives without requiring technical expertise in the field of AI.
Undergraduate Thesis
01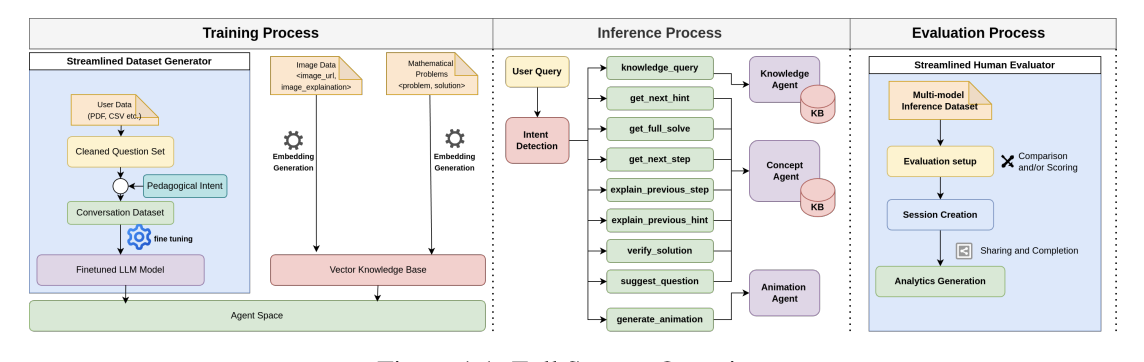
Enhancing Learning with Pedagogical Conversational Agents: A Human-Centered Approach
The rapid advancement of Large Language Models (LLMs) has opened new opportunities to transform various aspects of human life, including education. This thesis explores the integration of LLMs into teaching through the development of Pedagogical Conversational Agents (PCAs). We incorporate key capabilities such as vector search, image retrieval, code-generated animations, and supervised fine-tuning to create effective PCAs tailored to specific pedagogical objectives. The system that we propose, helps learners acquire core knowledge and deeper conceptual understanding with hint-based mathematical and analytical problem solving. Our approach is applied to K-12 physics, and we evaluate its effectiveness using multiple assessment frameworks. To ensure accessibility for educators with minimal technical expertise, we also implement a dual-platform system that enables non-technical K-12 teachers to create high-quality datasets, fine-tune models, and conduct human evaluations of the generated PCAs with students.
Public Sessions & Keynotes
I've had the previlege to be an AI spokesperson for different organizations, representing and empowering the youth :D
Programs
01
AI Ascend
August 2025GenAI Specialization for Banglalink Employees
Keynotes & Speaking Sessions
04
Campus To Corporate (University) Gamification & AI Session
2025AI Session for SJWS Students
Digitalyst AI Session
2025AI Session for Banglalink Digitalyst Interns
Campus To Corporate (SJWS) AI Session
2025AI Session for SJWS Students

Cracking the Case : From Strategy to Execution
2025IUT CBS's Biznation 2.0
Judgements & Mentorship
04
KBEC Nexus Season 2
November 2025Round 1 Judge

Consilium Challenge 2025
November 2025Round 1 Judge

Corporiddlerz by BUP Business and Communications Club
August 2025Round 1 Judge

CaseCation by Rajshahi University Business Club
September 2025Round 1 Judge
Education & Academic History
BSc(Engineering) in CSE
Bangladesh University of Engineering and Technology
Honors & Achievements
- 🏆Cumulative GPA 3.90
Scholarships
- 🎓Deans List in Level 4
- 🎓Deans List in Level 3
- 🎓Deans List in Level 2
- 🎓Deans List in Level 1
Higher Secondary Certificate(HSC)
Notre Dame College
Honors & Achievements
- 🏆Highest Marks in the country[1215/1300] (Among ~1.4M Students)
- 🏆Honorable Mention Award (Given to 9 out of ~2200 students)
- 🏆Certificate of appreciation , Geo Fest 2017,CMS, Lucknow, India
- 🏆Perfect Attendance Award
Scholarships
- 🎓Full Free Scholarship (3rd/2200 students) [Half Yearly Exam]
- 🎓Half Free Scholarship (5th/2200 students) [Sent Up-1]
Secondary School Certificate
Notre Dame College
Honors & Achievements
- 🏆93.85% marks in SSC
Scholarships
- 🎓Talentpool Scholarship in SSC(40th in Dhaka Board)
- 🎓Test Exam Scholarship(2nd/350 students) in 2017
- 🎓Udvashito Mukh SSC 2017 (86th)
- 🎓Pre-Test Exam Scholarship(1st/350 students) in 2016
- 🎓Yearly Exam Scholarship(2nd/350 students) in 2015
- 🎓Half Yearly Exam Scholarship(2nd/350 students) in 2015
- 🎓Talentpool Scholarship in JSC in 2014
- 🎓Test Exam Scholarship(1st/250 students) in 2014
- 🎓PEC Model Test Scholarship(1st/200 students) in 2011
Trophy Cabinet & Honors
I've spent most of my undergraduate pursuing excellence through differnt competitions (Hackathons, Robotics, Case Competitions) and have won almost everything that was humanly possible to win :D Winning for my country on multiple occassions is my proudest feat ;-;</p>

Honourable Mention 🏆
International Data Science Olympiad 2024, Amsterdam, Netherlands
Nov 2024

Champion 🏆
Bangladesh Blockchain Olympiad 2024(AI Track)
Sep 2024

Champion 🏆
Banglalink Ennovators 7.0
Dec 2023

Champion 🏆
Gen-dev Hackathon 2024, ACME AI
May 2024

Champion 🏆
SUST CSE Fest Hackathon, SUST
Feb 2024

Champion 🏆
Hult Prize at Army IBA 2023
Feb 2023

Champion 🏆
Mecheliness 1.0, AUST Mechanical Society
Feb 2023

Champion 🏆
Robo Carnival 2023, BUET Robotics Society
Jan 2023

Champion 🏆
Therap Javafest 2022
Aug 2022

Regional Champions 🏆
NASA Space Apps 2021
Oct 2021

1st Runners Up 🏆
Battle of Minds 2023, British American Tobacco
Aug 2023

1st Runners Up 🏆
SUST Technovent Hackathon 2023, SUST SWE Society
Jan 2023

1st Runners Up 🏆
Hult Prize Chittagong Summit 2021
Mar 2021

1st Runners Up 🏆
MIST Robo Cup
Jul 2020

2nd Runners Up 🏆
ITVerse Techtales
Nov 2023

2nd Runners Up 🏆
Codefest 2021, AIESEC Bangladesh
Dec 2021

2nd Runners Up 🏆
HackNSU, Season 3
Nov 2021

Top 6 🏆
Over the Wall, Marico Bangladesh
Oct 2023

Top 5 Startups 🏆
NEST 2021
Nov 2021
Media & Public Recognition
I've been featured in various national dailies and corporate pages for competitions, achievements and more :)
Featured In News





Featured Videos
BCOLBD 2024 Ending Ceremony
Few words from the organizers about the Gold Awardee Project from team BUET GRC lead by Salman Sayeed
Official Promo of 'On The Edge' by Banglalink
Promo Video of On The Edge, the team with members, Salman Sayeed(C), Hasrat Humayun, Nazifa Ahmed and Hanan Syed. This team later went on to become the title winner of Ennovators 7.0
Official Promo of 'Azor Ahai' by British American Tobacco Bangladesh
Promo Video of Azor Ahai, the team with members, Salman Sayeed, Azmain Bin Rashid(C), and Hasrat Humayun. This team later went on to become the 1st Runners Up of 20th Battle of Minds
Travel Memoirs & Exploration
This is my favourite section of this website where I have all of my fond memories of the 20 cities across 12 countries that I have visited. These journeys have shaped my perspective as a researcher and human being :D